Flink之Sink
本文共 8689 字,大约阅读时间需要 28 分钟。
Flink没有类似于spark中的foreach方法,让用户进行迭代的操作。对外的输出操作要利用Sink完成。最后通过类似如下方式完成整个任务最终输出操作。
stream.addSink(new MySink(XX))
官方提供了一部分的框架的sink。除此之外,需要用户自定义实现sink。
一、输出到Kafka
1.1 代码
public class SinkTest1_Kafka { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// env.setParallelism(1); // 从文件中读取数据 DataStream inputStream = env.readTextFile("/Users/sundongping/IdeaProjects/FirstFlinkTest/src/main/resources/sensor.txt"); inputStream.print("input"); // 转换成SensorReading类型 // java8 中的lamda表达式 DataStream dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])).toString(); }); dataStream.addSink(new FlinkKafkaProducer011 ("localhost:9092", "sinktest", new SimpleStringSchema())); env.execute(); }} 1.2 启动Kafka消费者
./bin/./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sinktest
1.3 运行程序,Kafka消费数据

启动Kafka生产者:
./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic sensor
Kafka作为数据源的代码:
public class SinkTest1_Kafka { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // kafka配置项 Properties properties = new Properties(); properties.setProperty("bootstrap.servers", "localhost:9092"); properties.setProperty("group.id", "consumer-group"); properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); properties.setProperty("auto.offset.reset", "latest"); // 从kafka中读取数据 DataStream inputStream = env.addSource(new FlinkKafkaConsumer011 ("sensor", new SimpleStringSchema(), properties)); // 转换成SensorReading类型 // java8 中的lamda表达式 DataStream dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])).toString(); }); dataStream.addSink(new FlinkKafkaProducer011 ("localhost:9092", "sinktest", new SimpleStringSchema())); env.execute(); }} 启动Kafka消费者:
如上所示效果:

二、输出到Redis
2.1 pom.xml文件中引入flink与redis的连接器
org.apache.bahir flink-connector-redis_2.11 1.0
2.2 代码
public class SinkTest2_Redis { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// env.setParallelism(1); // 从文件中读取数据 DataStream inputStream = env.readTextFile("/Users/sundongping/IdeaProjects/FirstFlinkTest/src/main/resources/sensor.txt"); // 转换成SensorReading类型 // java8 中的lamda表达式 DataStream dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); // 定义Jedis连接配置 FlinkJedisPoolConfig config = new FlinkJedisPoolConfig.Builder() .setHost("localhost") .setPort(6379) .build(); dataStream.addSink(new RedisSink<>(config, new MyRedisMapper())); env.execute(); } // 自定义RedisMapper public static class MyRedisMapper implements RedisMapper { // 定义保存数据到Redis的命令,存成Hash表,使用hset命令创建sensor_temp 哈希表,数据包括id、temperature @Override public RedisCommandDescription getCommandDescription() { return new RedisCommandDescription(RedisCommand.HSET, "sensor_temp"); } @Override public String getKeyFromData(SensorReading data) { return data.getId(); } @Override public String getValueFromData(SensorReading data) { return data.getTemperature().toString(); } }} 2.3 启动Redis服务端和客户端
启动服务端
cd redis安装包的src目录./redis-server
启动客户端
cd redis安装包的src目录./redis-clikeys *
结果如下

2.4 启动程序
再次执行keys *命令,结果如下
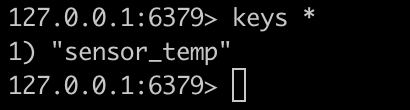 查看某一具体数据,执行
查看某一具体数据,执行hget sensor_temp sensor_1命令,结果如下  查看全部数据,执行
查看全部数据,执行hgetall sensor_temp命令,结果如下 
三、输出到ES
3.1 pom.xml文件中引入flink与es的连接器
org.apache.flink flink-connector-elasticsearch6_2.12 1.10.1
3.2 代码
运行下面的代码
public class SinkTest3_ES { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// env.setParallelism(1); // 从文件中读取数据 DataStream inputStream = env.readTextFile("/Users/sundongping/IdeaProjects/FirstFlinkTest/src/main/resources/sensor.txt"); // 转换成SensorReading类型 // java8 中的lamda表达式 DataStream dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); // 定义es的连接配置 ArrayList httpHosts = new ArrayList<>(); httpHosts.add(new HttpHost("localhost", 9200)); dataStream.addSink(new ElasticsearchSink.Builder (httpHosts, new MyEsSinkFunction()).build()); env.execute(); } // 实现自定义的ES写入操作 public static class MyEsSinkFunction implements ElasticsearchSinkFunction { @Override public void process(SensorReading sensorReading, RuntimeContext runtimeContext, RequestIndexer requestIndexer) { // 定义写入的数据source HashMap dataSource = new HashMap<>(); dataSource.put("id", sensorReading.getId()); dataSource.put("temp", sensorReading.getTemperature().toString()); dataSource.put("ts", sensorReading.getTimestamp().toString()); // 创建请求,作为向ES发起的写入命令 IndexRequest indexRequest = Requests.indexRequest() .index("sensor") .type("readingdata") .source(dataSource); // 用index发送请求 requestIndexer.add(indexRequest); } }} 3.3 启动ES并查看数据
四、输出到Mysql
JDBC 自定义 Sink
4.1 pom.xml
mysql mysql-connector-java 5.1.48
4.2 代码
public class SinkTest4_JDBC { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// env.setParallelism(1); // 从文件中读取数据 DataStream inputStream = env.readTextFile("/Users/sundongping/IdeaProjects/FirstFlinkTest/src/main/resources/sensor.txt"); // 转换成SensorReading类型 // java8 中的lamda表达式 DataStream dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); dataStream.addSink(new MyJdbcSink()); env.execute(); } public static class MyJdbcSink extends RichSinkFunction { //声明连接和预编译语句 Connection connection = null; PreparedStatement insertStmt = null; PreparedStatement updateStmt = null; // open属于生命周期,避免在invoke()中来一条数据就创建一次数据库连接 @Override public void open(Configuration parameters) throws Exception { connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "123456"); insertStmt = connection.prepareStatement("insert into sensor_temp (id, temp) values (?, ?)"); updateStmt = connection.prepareStatement("update sensor_temp set temp = ? where id = ?"); } // 每来一条数据,调用连接,执行sql @Override public void invoke(SensorReading value, Context context) throws Exception { // 直接执行更新语句,如果没有更新就执行插入 updateStmt.setDouble(1, value.getTemperature()); updateStmt.setString(2, value.getId()); updateStmt.execute(); if(updateStmt.getUpdateCount() == 0){ insertStmt.setString(1, value.getId()); insertStmt.setDouble(2, value.getTemperature()); insertStmt.execute(); } } @Override public void close() throws Exception { insertStmt.close(); updateStmt.close(); connection.close(); } }} 转载地址:http://kyxii.baihongyu.com/
你可能感兴趣的文章
DirectX11 HLSL打包(packing)格式和“pad”变量的必要性
查看>>
DirectX11 光照演示示例Demo
查看>>
漫谈一下前端的可视化技术
查看>>
VUe+webpack构建单页router应用(一)
查看>>
Vue+webpack构建单页router应用(二)
查看>>
从头开始讲Node.js——异步与事件驱动
查看>>
Node.js-模块和包
查看>>
Node.js核心模块
查看>>
express的应用
查看>>
NodeJS开发指南——mongoDB、Session
查看>>
Express: Can’t set headers after they are sent.
查看>>
2017年,这一次我们不聊技术
查看>>
实现接口创建线程
查看>>
Java对象序列化与反序列化(1)
查看>>
HTML5的表单验证实例
查看>>
JavaScript入门笔记:全选功能的实现
查看>>
程序设计方法概述:从面相对象到面向功能到面向对象
查看>>
数据库事务
查看>>
JavaScript基础1:JavaScript 错误 - Throw、Try 和 Catch
查看>>
SQL基础总结——20150730
查看>>